[
Date Prev][
Date Next][
Thread Prev][
Thread Next][
Date Index][
Thread Index]
[
List Home]
|
Re: [mylyn-integrators] AbstractTask vs. RepositoryTaskData in aconnector
|
> I think that's the right way to do it, especially if you have that many
> attributes it makes sense to store the complete task information in
> separate classes and keep the information in the MyTrackerTask minimal
> (only what'r required by the framework). But to be honest I don't know
> how severly this affects performance, because I don't have that many
> fields.
It is desirable to keep the number of attributes on the task class to a
minimum. Only information that is needed for decoration, sorting, grouping
etc. in the task list should be available from that object. If additional
information is needed, e.g. to display incoming changes in the task list
tooltip, the tasks framework will load the full task data on-demand for a
task from the offline storage. This is reasonably fast but does not scale to
a large number of tasks.
It should also be considered that the task list is serialized to a single XML
file. This can grow to multiple MB (uncompressed) in size even with the
limited default task model used by the Bugzilla connector.
In terms of memory overhead I have only done limited profiling. I have seen
the tasklist use up to 10 MB of heap space for ~6000 Bugzilla tasks.
> Tom Bryan (tombry) wrote:
> > Dennis Rietmann wrote on Tuesday, May 13, 2008 4:52 AM:
> >> just a small comment: Whether to use a completely custom class to
> >> store a task received from a repository (e.g. TrackTicket) or use a
> >> class that extends the AbsractTask depends on your modeling of tasks.
> >> If the AbstractTask is compatible with your tasks' model you might as
> >> well use it and end up with 2 representations:
> >> * MyTrackerTask extends AbstractTask
> >> * TaskData
> >>
> >> This might make things easier since you only have to deal with 1
> >> mapping (I did this with the origo connector and it worked quite
> >> well).
> >
> > Thanks, Dennis. That's what I was trying to do, following the Origo
> > example. I do have an additional representation since I'm using JAXB to
> > suck XML documents into Java, but the JAXB representation does not get
> > out of the service client class.
> >
> > The thing that I was wondering was whether to put all of my attributes
> > in the MyTrackerTask that extends AbstractTask. For example, in my
> > repository, I may have over 100 attributes for a task. All of those
> > attributes must be stored in the RepositoryTaskData instance for the
> > task, but it looked like some other connectors only put a few core
> > fields in their AbstractTask subclass. I suppose that would make the
> > Task List take less memory, and then the rest of the attributes could be
> > fetched when the task is opened in the editor. Of course, I'm still not
> > sure whether it really works that way. :)
Yes, that is the idea. The task data is the full set of attributes that is
loaded on-demand.
> > For now, I decided to stuff all of the attributes in MyTrackerTask
> > (extends AbstractTask) because I'm also using that class to shuttle data
> > from my service client to the RepositoryTaskData instance. After I have
> > all of that actually working, I figured that I could go back and make
> > the Task List representation for my class smaller/lighter.
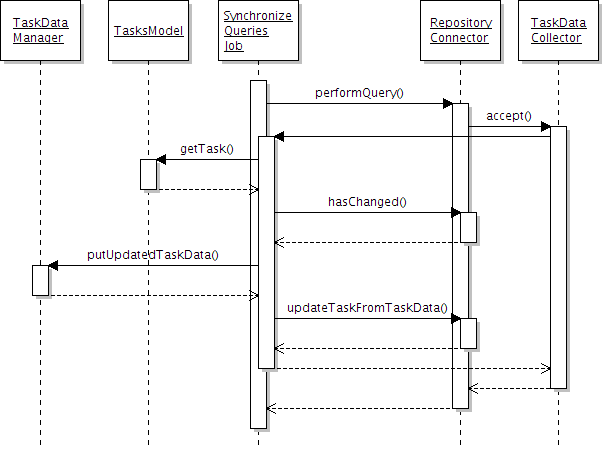
I have attached a simplified sequence diagram to clarify the synchronization
process. It shows how query results are processed in Mylyn 3.0: The tasks
framework receives TaskData objects from the connector. The tasks framework
then determines if the task in the task list needs updating and updates the
offline store, task state etc. if that is the case.
Steffen
--
Steffen Pingel - steffenp@xxxxxx - http://steffenpingel.de
Attachment:
synchronize-query.png
Description: PNG image
{kind=link}