Thanks for taking the initiative here. Great to see. Like others on
this thread, I am all for making things easier so this is interesting.
Some clarifying questions / observations if you will...
- Context setting... We made a very explicit decision that the data
formats, schemas, ... underlying IUs, repositories, artifact
descriptors, ... are not to be API. The fact that metadata repos
currently are written as xml files is a mere happenstance of the
current implementation. The content, structure and form of that can
change from repo to repo (one might be XML, another a database, another
a RESTful service, another, ..). The important bits are the IUs (in
the case of metadata). So things like "content.xml export actions"
don't seem to fit well. (see my next point on the publisher)
- The tooling effort around p2 should be coordinated with the
publisher. The idea behind the publisher is to support the easy
publication of IUs and artifacts into repos. There are a wide variety
of publishing actions and advice types that consume files, markup,
state, ... and write to repos. Ideally authors of metadata actually
have to do very little work as the actions would do the heavy lifting.
In cases where there are no actions or the information required is
simply missing, authors can advise actions or craft IUs from whole
cloth. The authored form of advice is similarly unspecified.
Ultimately all the publisher (well the actions) care about is that they
have instances of the I*Advice interfaces they care about and use to do
their job. Note as well that the publisher is used at development time
to create/add-to repos and at runtime when watching dropins folders and
the like. It is even concieved that you can deploy advice that would
advise the publisher should it ever see a related publishing action
(e.g., advising the dropins folder to add some property to all all
bundles it discovers and publishes).
- The work that the EMF team has done to keep the core small and
running on small footprint JREs is great. It would be interesting to
know what the size tradeoffs are here. Will we save some space by
using EMF code rather than our own? In your experience, what would the
net code space cost/savings be? While it is easy to say its just
another NNNk, we do have to be aware that size does count. There are
teams looking to use p2 in embedded environments etc.
- What if any is the impact of the use of EMF for authoring on the
runtime use of p2? For example, what p2 bundles would you expect to
depend on EMF? Is there any opportunity to make the dependencies
optional?
- As Pascal pointed out, most of the APIs in this space are read-only.
Can we use this characteristic to some advantage here?
- You talked about exposing the p2 engine as an EMF API. Can you
clarify what that would mean? What would it enable? Also to clarify,
do you mean IEngine?
Thanks again
Jeff
Benjamin CABÉ wrote:
Hi
all,
We've made some further work on the "p2 authoring tools" and developed
an early prototype of a metadata repository editor, which is quite
similar to what the "Update site editor" proposes.
A requirement document has been initialized on the wiki
(http://wiki.eclipse.org/Equinox_p2_Metadata_Repository_Authoring).
We'd like to have some feedback from the p2 community about the choice
we made to use an EMF model behind the editor, to ease the GUI
development (databinding, EMF content & label providers, undo/redo,
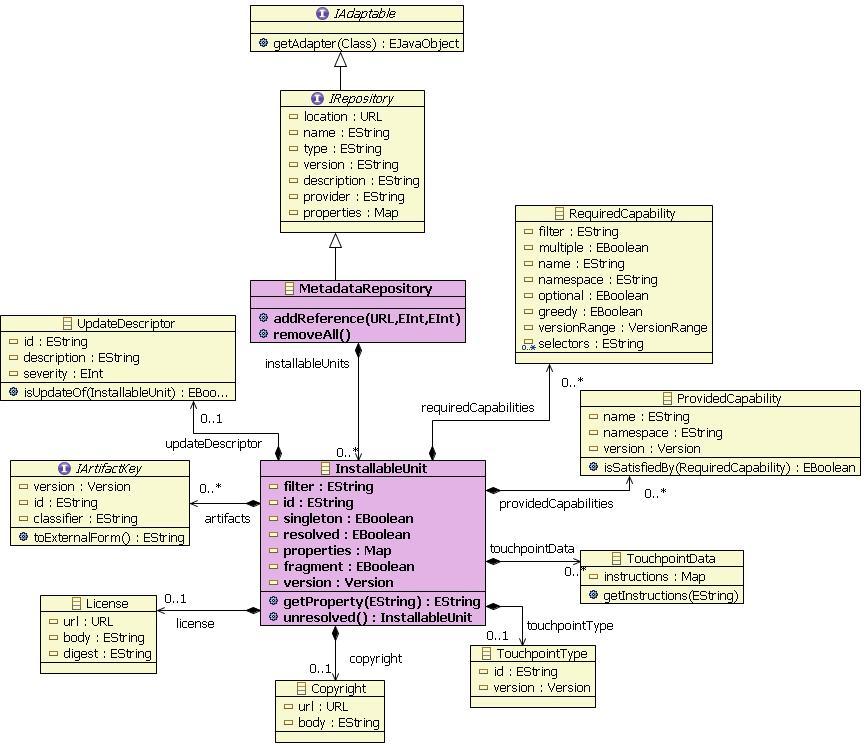
...). This model is very close to the p2 API (see attached class
diagram).
At the moment, what we've done is to bind the editor to our metadata
repository "EObject", and propose a "content.xml export" action that
converts our EMF model to p2 API classes. This is something very
trivial, and that works well, *but* we think it would be great to think
about having the p2 engine directly available as an EMF API.
Some work has already been done to make EMF Core, Edit, and Edit.UI
Foundation 1.1 compatible (see bug #215378) ; and the discussion about
having
more EMF inside e4 (e.g. an EMF workbench model) came to the
conclusion, AFAIK,
that EMF is kind of great and can keep a very tiny footprint.
In the p2 context, having an EMF model would allow :
- more trivial XML
serialization/unserialization
- listening to model changes
- UI writing simplified (a lot!)
- Databinding
- Undo/Redo
- Treeviewers, labelproviders, etc.
much simpler using the
EMF.Edit layer
From what we have seen, most of the p2 API
(IMetadataRepository,
IInstallableUnit, ...) have implementations that are quite
straightforward (getters and setters directly bound to their underlying
attribute), and the constructors could easily be replaced by the EMF
generated factories.
What do you, p2 gurus, think about having more EMF in p2? Is it
something that has already been discussed?
Cheers,
Benjamin.
_______________________________________________
p2-dev mailing list
p2-dev@xxxxxxxxxxx
https://dev.eclipse.org/mailman/listinfo/p2-dev
|
